AI‑Kubeflow Pipeline‑2
Training, Evaluation & Model Selection · Kubernetes‑Native MLOps
Production‑style ML training and evaluation pipelines using Kubeflow Pipelines with containerized components, artifact lineage, and metric‑driven model selection (KFP v2, MinIO, MLMD).
Project Summary
MLOps / Platform Engineering
Category
AI + MLOps + Platform Engineering (Kubernetes / Kubeflow)
Industry
Cross‑industry Enterprise AI Platforms / MLOps Infrastructure
Domain
Model Training Engineering / Pipeline Orchestration
Key Technologies & Concepts
Kubeflow native keywords
MLOps keywords
Problem & Objective
Why this project exists
Problems Solved
- Notebook‑driven training lacks reproducibility & governance
- Manual execution → inconsistent environments, fragmented metrics
- Limited visibility into experiment lineage and outcomes
Primary Objective
- Reproducible, pipeline‑driven ML training & evaluation on Kubeflow
- Containerized components + standardized artifact storage + metric‑driven model selection
Solution & Architecture
Kubeflow pipeline flow
Orchestration overview
Kubeflow Pipelines workflow orchestrates multiple containerized components for data ingestion, model training (Logistic Regression and Decision Tree), and evaluation. Each pipeline run produces versioned artifacts and metrics, enabling systematic comparison and model selection based on evaluation criteria.
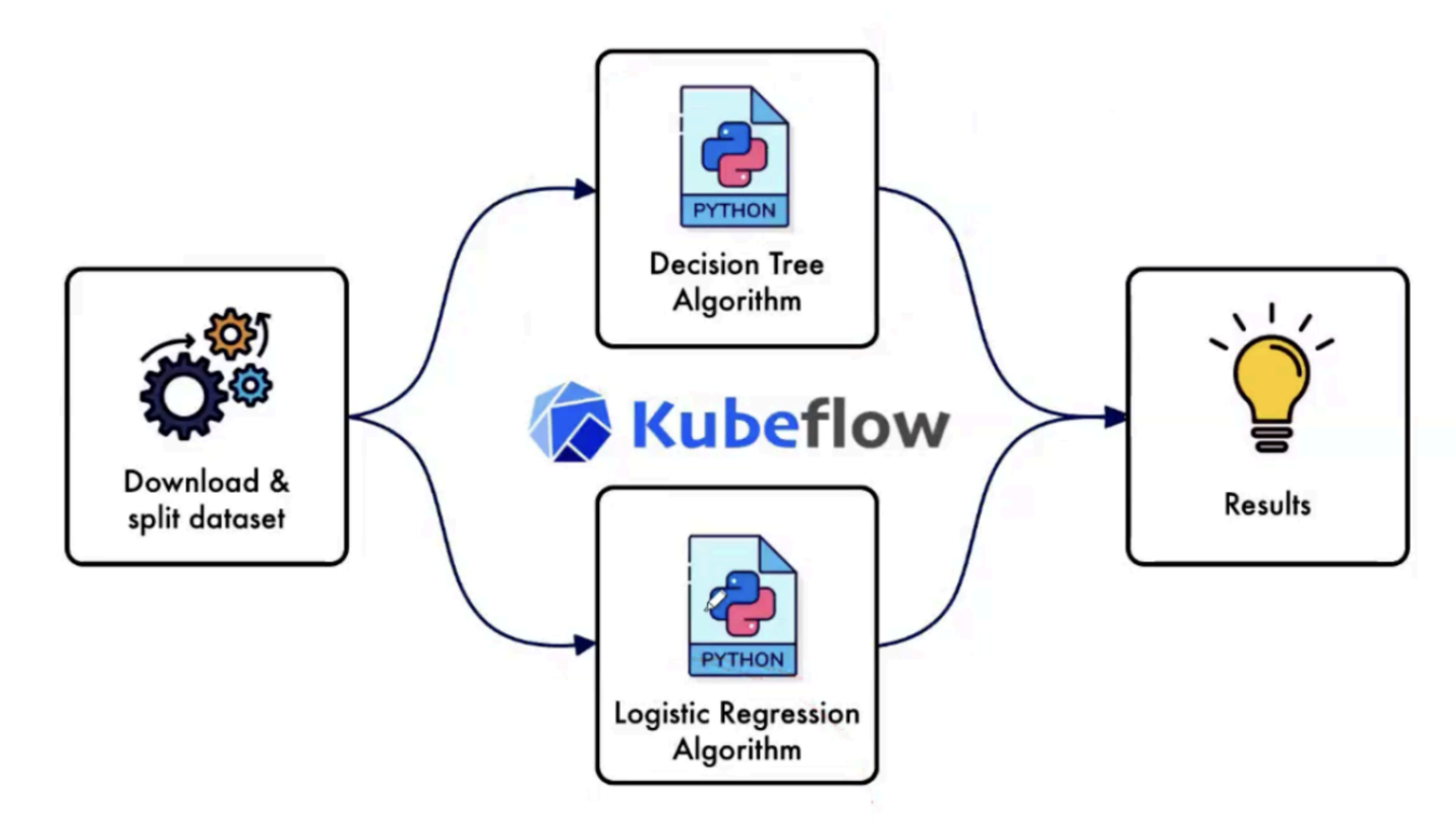
Components
- Download data (component)
- Training (scikit‑learn containers)
- Evaluation metrics (accuracy)
- Kubeflow Pipelines orchestration
- MinIO artifact storage
Platform & services
- Kubernetes + Kubeflow (KFP v2 runtime)
- Argo Workflows (execution engine)
- Docker (containerized training components)
- MinIO artifact storage for datasets and outputs
- Kubeflow Metadata Store (MLMD) for lineage and run metadata
- Kubernetes Pods, Services, Namespaces, RBAC
Scalability & reliability
- Stateless pipeline components executed as isolated pods
- Retry and failure isolation at step level
- Artifact durability via object storage (MinIO)
- Re-runnable pipelines with deterministic environments via image versioning
AI / DevOps Details
Automation, orchestration, and observability
AI/ML focus
Model Training, Evaluation & Experiment Orchestration (MLOps – Offline Training).
Pipeline automation
- Automated data ingestion component
- Parallel/serial training components (Logistic Regression, Decision Tree)
- Metric computation and logging (accuracy)
- Metric-based model comparison and selection
- Pipeline as code (compiled KFP YAML)
CI/CD & orchestration
- Docker training component images
- Kubeflow Pipelines orchestration
- Argo Workflows pipeline execution
- Kubernetes runtime scheduling
Monitoring & optimisation
- Kubeflow Pipelines UI for run status, DAG visualization, and step-level logs
- Kubernetes pod logs for component-level debugging
- ML Metadata Store for run lineage and artifact traceability
- Metric visibility (accuracy) across experiments for comparative analysis
- Failure isolation and targeted re-runs of failed steps
Skills & Technologies
Proficiencies demonstrated
Primary skills
- Kubeflow Pipelines (advanced)
- Kubernetes‑Native MLOps (advanced)
- ML Training Pipeline Design (advanced)
- Experiment Tracking & Lineage (advanced)
Secondary tools
- scikit‑learn (model framework)
- Docker (containerization)
- YAML (pipeline/component specifications)
- Argo Workflows
- MinIO, ML Metadata
- Kubeflow UI / SDK
- Docker Hub
Programming languages
Python (primary), YAML (pipeline/component specs).
Kubeflow DevOps — Architecture & YAML mapping
Reference: Pipeline‑2 modelling
| Architecture Block | Kubeflow CI/CD / MLOps Construct (Pipeline‑2) |
|---|---|
| Source Repository | GitHub (Kubeflow modeling / pipelines repo) |
| Source Trigger | Manual trigger (Kubeflow UI / SDK) or CI trigger (GitHub Actions / local pipeline submission) |
| CI Runner | GitHub Actions Linux Runner (ubuntu-latest) (optional for CI-driven pipeline compilation and submission) |
| Build / Pipeline Execution | Kubeflow Pipelines (KFP v2: Data → Train → Evaluate → Condition) |
| Training Orchestration | Kubeflow Pipelines (KFP v2 running on Kubernetes via Argo Workflows) |
| Data Processing | Kubeflow Pipeline Component (Python + scikit‑learn preprocessing in containerized step) |
| Model Evaluation | Kubeflow Pipeline Component (Python + scikit‑learn evaluation component; accuracy metric) |
| Artifact Storage | MinIO (S3-compatible object store for datasets, model artifacts, metrics JSON) |
| Container Registry | Docker Hub (versioned training component images) |
| Model Registry | Kubeflow Pipelines run history + ML Metadata Store (MLMD) + MinIO artifact versions (open-source equivalent of managed model registries) |
| Approval Gate | Pipeline Condition (metric threshold gate for downstream deployment pipeline) |
| Security & Auth | Kubernetes Service Accounts + RBAC (least-privilege execution identity for pipeline pods) |
| Secrets / Config | Kubernetes Secrets + Environment Variables (mounted into pipeline containers) |
| Monitoring & Logs | Kubeflow Pipelines UI + Kubernetes Pod Logs (per-step execution logs) |
| Lineage & Governance | Kubeflow Pipelines lineage + ML Metadata Store (inputs/outputs, run lineage, artifact traceability) |
| Infrastructure Backend | Self-managed Kubernetes (Minikube / EKS / AKS / GKE) hosting Kubeflow Pipelines runtime (control plane + workflow engine deployed via Kubeflow manifests) |
Pipeline‑2 implements Kubernetes‑native ML training and evaluation using Kubeflow Pipelines, providing the open-source equivalent of managed Vertex AI Pipelines for model experimentation, metric-based selection, and governed promotion to deployment workflows.
Challenges & Resolutions
Technical hurdles
Key challenges
- Packaging training code into reproducible container images
- Wiring artifact paths between components
- Consistent metric logging across variants
- Experiment lineage and traceability
Resolutions
- Standardised Dockerfiles per component
- Kubeflow artifact inputs/outputs for clean handoffs
- Centralised accuracy logging for model comparison
- ML Metadata Store + KFP run history
Assets & References
Code, diagrams, study material
Kubeflow Official Documentation Repo
Official Kubeflow Pipelines repository and documentation source.
kubeflow/pipelinesKubeflow Pipelines MLOps
Project repository for Kubeflow Pipelines MLOps implementation.
Kubeflow-pipelines-MLOpsNote: Additional project materials (KFP v2 YAML, component specs) are shared selectively for interview / evaluation.